
Entender las redes neuronales profundas para transformar el sector de las infraestructuras

27 de marzo de 2024
En cuestión de unos años, la innovación y la tecnología han transformado el uso que hacemos de las imágenes y los vídeos. Las cámaras ya no solo sirven para grabar, sino que tienen la capacidad de reconocer objetos y hasta de representar su trayectoria. Detrás de esto están la gran evolución de las cámaras, pero sobre todo la inteligencia artificial y, más concretamente, la visión por computador basada en redes neuronales profundas.
Conocer el funcionamiento de estas redes neuronales profundas nos permite no solo aprovechar su potencial, sino también seguir ampliando el amplio abanico de usos que ya tienen en el campo de las infraestructuras.
El principio: las técnicas clásicas de analítica de imágenes
Para entender cómo se han analizado y modificado las imágenes y los videos digitales en las últimas décadas, lo mejor es empezar por el principio. ¿Cómo funcionan? Si nos centramos en las imágenes digitales en blanco y negro, vemos que están formadas por una matriz de dos dimensiones: ancho y alto. Los valores de la matriz se mueven en un rango (denominado profundidad del color) que representa los diferentes tonos de gris que puede tener cada píxel.
Habitualmente, esta profundidad del color varía entre el valor 0, que es el negro, y el 255, que es el blanco. Entre estos dos números, se abre todo un gran abanico de tonos. La siguiente imagen nos muestra cómo se digitalizaría una imagen en blanco y negro:

Si la imagen tiene color, se representa mediante una matriz de tres dimensiones. En este caso, la profundidad del color representa el rojo, el verde y el azul, los tres colores que componen el modelo RGB (red, green, blue, por sus siglas en inglés). Los valores de cada pixel varían entre el 0, el negro, y el 255, que puede ser el rojo, el verde o el azul. De este modo, se pueden obtener más de 16 millones de colores.

Un vídeo digital, por otro lado, es una secuencia de imágenes o fotogramas en una unidad de tiempo determinada. El valor más habitual es de 30 fps (frames per second), lo que significa que cada segundo de vídeo está compuesto por 30 imágenes. Y, dado que estas imágenes están formadas por valores, basta con realizar operaciones matemáticas para modificarlas.
Si quisiéramos aclarar una imagen en blanco y negro, por ejemplo, deberíamos sumarles un número fijo a todos los píxeles de la imagen, ya que de esa manera estarán más cercanos al valor 255 y, por consiguiente, al color blanco.
Esta lógica también nos permitiría realizar comparaciones entre una imagen y la siguiente: las partes de la imagen que cambian tienen valores distintos, mientras que las partes sin cambios mantienen valores similares. En esto se basan los algoritmos de sustracción de fondo, que diferencian entre los píxeles de un vídeo que tienen valores constantes (los del fondo) de los que varían (los de los objetos en movimiento).
De este modo, estos algoritmos permiten identificar la parte de un vídeo que cambia con el tiempo. La siguiente imagen muestra el resultado aplicar un algoritmo de sustracción de fondo sobre una secuencia de imágenes de los túneles de la M-30 en Madrid:

La revolución de las redes neuronales
En los últimos años, la inteligencia artificial y, más concretamente, las redes neuronales profundas han hecho posible mejorar las técnicas de reconocimiento de imágenes. Las redes neuronales son herramientas inspiradas en el funcionamiento del cerebro humano. Las siguientes imágenes muestran la representación de una neurona y su simplificación matemática:
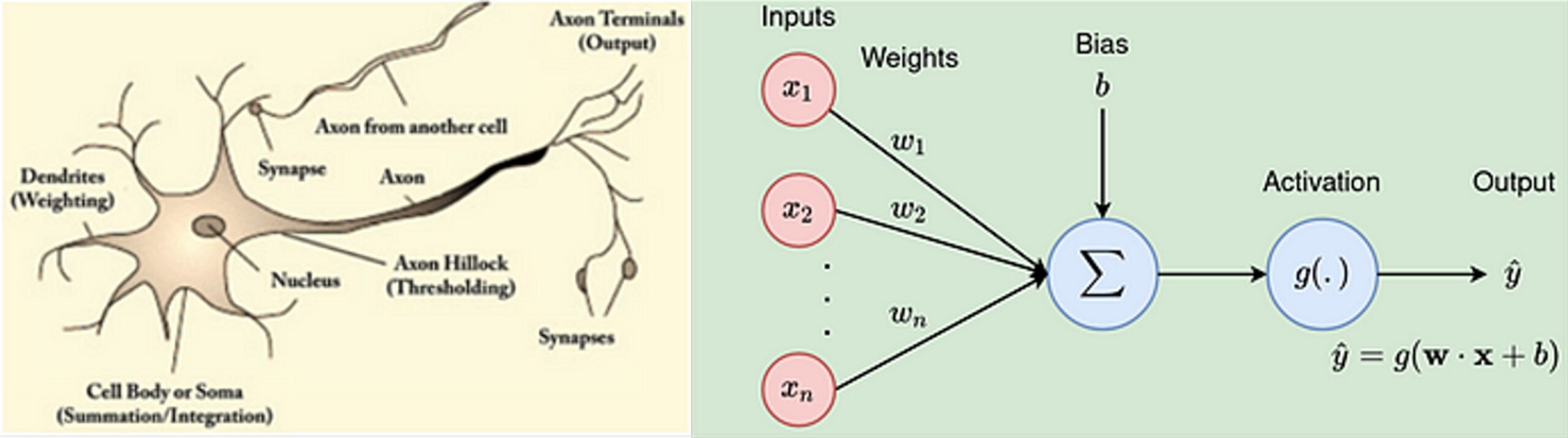
El funcionamiento de las redes neuronales, a grandes rasgos, es el siguiente: una neurona recibe impulsos eléctricos a través de las dendritas. El funcionamiento de la neurona permite dar mayor o menor importancia a estos impulsos y, por consiguiente, generar una respuesta diferente para cada uno de ellos.
En el modelo matemático, las entradas o inputs equivalen a las dendritas de las neuronas reales. Y, del mismo modo, todo el sistema genera una respuesta determinada a cada impulso. Cuando un proceso se repite en multitud de capas que cuentan con varios cientos de neuronas cada una, se forma lo que se denomina una red neuronal artificial profunda.
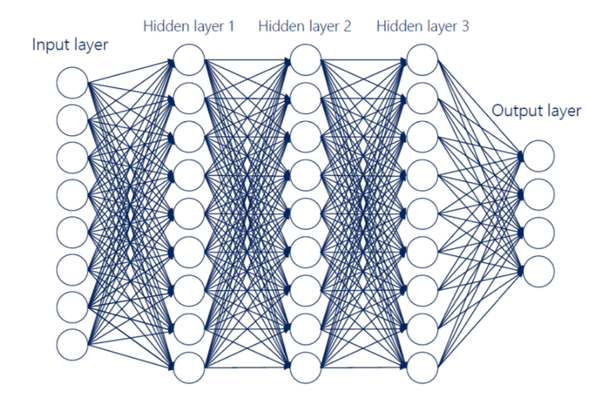
En estas redes neuronales, cada neurona se especializa en la detección de un determinado patrón de datos. Cuando los datos de entrada coinciden en gran medida con lo que la neurona espera, esta genera una señal de gran intensidad, es decir, un valor de salida elevado. En cambio, si apenas coinciden, la salida de la neurona será baja o nula. Esto se reproduce capa tras capa, extendiéndose hasta el final de la red, donde se genera el resultado.
¿Y cómo se consigue que una red sea capaz de hacer esta relación? Entrenándola. En el caso de las imágenes, este entrenamiento se realiza introduciendo en la red un conjunto de imágenes previamente clasificadas y ajustando los parámetros para que el resultado sea el esperado.
Sería un proceso asimilable al que se realiza al ajustar el sonido antes de un evento musical. El técnico sabe cómo debe sonar un determinado instrumento y para ello actúa sobre diferentes controles de forma iterativa hasta que el sonido es el deseado.

Para entrenar redes neuronales es necesario disponer de un número ingente de imágenes (o cualquier otro input) etiquetadas, algo muy costoso computacionalmente. Por ello, es habitual utilizar redes preentrenadas, en las que solo es necesario realizar un ajuste fino de los parámetros para adecuarlas lo máximo posible a la tarea a desempeñar. Esto se le conoce como transfer learning y permite obtener muy buenos resultados con poco tiempo de entrenamiento.
Algunos ejemplos de redes preentrenadas muy utilizadas son YOLO, MobileNet o EfficientDet. Muchas de ellas proceden de grandes corporaciones como Google, que las pone a disposición de la comunidad para su uso. Algunas empresas también ofrecen redes preentrenadas como producto y otras entrenan sus propias redes para un uso determinado.
Una vez la red está entrenada, puede ser muy ligera y ágil, lo que permite su uso en tiempo real en dispositivos muy sencillos, como teléfonos móviles o cámaras de videovigilancia.
La aplicación de redes neuronales a las cámaras de tráfico
La innovación ha permitido revolucionar las aplicaciones de las redes neuronales profundas y darles usos muy útiles. Un ejemplo lo encontramos en las cámaras de tráfico, que permiten identificar y clasificar diferentes tipos de vehículos, otros objetos y seres vivos con cierta confianza.
Además, estas cámaras también logran interpretar y registrar las trayectorias de los objetos. Es habitual que estos modelos vayan acompañados de algoritmos de localización relativa dentro de la imagen, de manera que el objeto identificado quede, por ejemplo, inscrito en un rectángulo.
Con la posición relativa de los rectángulos en la imagen y mediante el empleo de algoritmos de seguimiento o tracking, es posible representar las trayectorias de los objetos, como se observa en la siguiente imagen.
![]()
Esto tiene numerosas aplicaciones. Permite cuantificar, por ejemplo, cuántos vehículos sobrepasan una línea o cuántos se encuentran en el interior de un polígono durante un tiempo determinado.
La inteligencia artificial y concretamente las redes neuronales profundas han encontrado múltiples aplicaciones en nuestro día a día. Permiten resolver tareas repetitivas y complejas en poco tiempo y con resultados muy satisfactorios. Conocer bien su funcionamiento abre un amplísimo abanico de usos en el campo de las infraestructuras y, lo que es igual de importante, permite seguir ampliándolo.



Todavía no hay comentarios