
Understanding deep neural networks to transform the infrastructure sector

27 of March of 2024
In a matter of just a few years, innovation and technology have transformed the way we use images and videos. Cameras are not only used to record, but also have the ability to recognize objects and even to represent their trajectory. Behind this lies the great evolution in cameras, but also artificial intelligence and, more specifically, computer vision based on deep neural networks.
Understanding how these deep neural networks work allows us not only to take advantage of their potential, but also to continue expanding the wide range of uses they already have in the field of infrastructure.
The principle: classical image analysis techniques
To understand how digital images and videos have been analyzed and modified in recent decades, it is best to start at the beginning. How do they work? If we focus on black and white digital images, we see that they consist of a two-dimensional field: width by height. The values of the field of pixels moves in a range (called color depth) that represents the different shades of gray that each pixel can have.
Typically, this color depth ranges from 0, which is black, to 255, which is white. Between these two numbers lie a wide range of shades. The following image shows how a black and white image would be digitized:

If the image is in color, it is represented by a three-dimensional field. In this case, the color depth represents red, green and blue, the three colors that make up the RGB (red, green, blue) model. The values of each pixel vary between 0, black, and 255, which can be red, green or blue. In this way, more than 16 million colors can be obtained.

A digital video, on the other hand, is a sequence of images or frames in a given unit of time. The most common value is 30 fps (frames per second), which means that each second of video is composed of 30 images. And, since these images are made up of values, mathematical operations are sufficient to modify them.
If we wanted to lighten a black and white image, for example, we could add a fixed number of white to all pixels in the image, as this will bring them closer to the value 255 and thus to the color white.
This logic would also allow us to make comparisons between one image and the next: the parts of the image that change have different values, while the unchanged parts maintain similar values. This is the basis of background subtraction algorithms, which differentiate between pixels in a video that have constant values (those of the background) and those that vary (those of moving objects).
In this way, these algorithms make it possible to identify the part of a video that changes over time. The following image shows the result of applying a background subtraction algorithm on a sequence of images of the M-30 tunnels in Madrid:

The revolution of neural networks
In recent years, artificial intelligence and, more specifically, deep neural networks have made it possible to improve image recognition techniques. Neural networks are tools inspired by the functioning of the human brain. The following images show the representation of a neuron and its mathematical simplification:
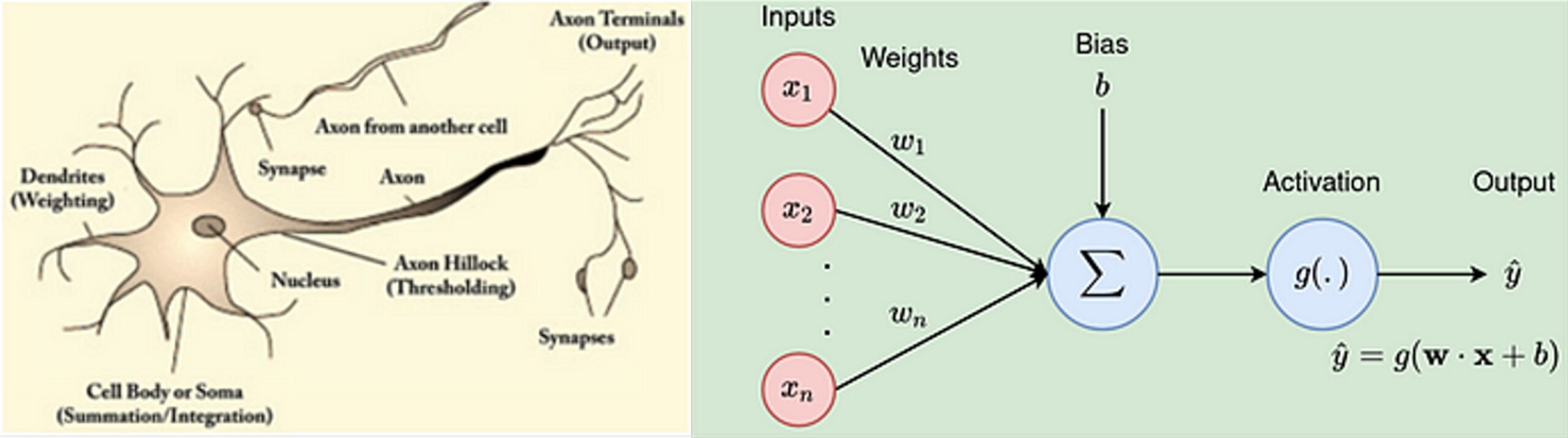
The operation of neural networks, broadly speaking, is as follows: a neuron receives electrical impulses through dendrites. The functioning of the neuron makes it possible to give greater or lesser importance to these impulses and, consequently, to generate a different response to each of them.
In the mathematical model, the inputs are equivalent to the dendrites of real neurons. And similarly, the entire system generates a specific response to each impulse. When a process is repeated in a multitude of layers with several hundred neurons each, what is called a deep artificial neural network is formed.
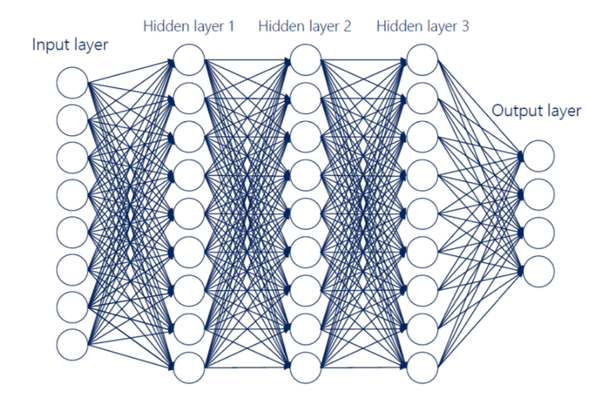
In these neural networks, each neuron specializes in the detection of a certain data pattern. When the input data largely match what the neuron expects, the neuron generates a signal of high intensity, i.e. a high output value. On the other hand, if they barely coincide, the neuron output will be low or null. This is reproduced layer after layer, extending to the end of the network, where the result is generated.
And how do you get a network to be able to make this kind of relationship? By training it. In the case of images, this training is performed by introducing a set of previously classified images into the network and adjusting the parameters so that the result is as expected.
It is a process similar to that of tuning up before a concert. The technician knows how a certain instrument should sound and therefore iteratively acts on different controls until the desired sound is achieved.

To train neural networks it is necessary to have a huge number of labeled images (or any other input), which is computationally very expensive. For this reason, it is common to use pre-trained networks, in which only a fine adjustment of the parameters is necessary to adapt them to the task to be performed. This is known as transfer learning and allows you to obtain very good results with little training time.
Some examples of highly used pre-trained networks are YOLO, MobileNet and EfficientDe. Many of these come from large corporations like Google, which makes them available to the community for use. Some companies also offer pre-trained networks as a product for purchase and others train their own networks for a specific use.
Once the network is trained, it can be very lightweight and agile, allowing it to be used in real time on very simple devices such as cell phones or video surveillance cameras.
The application of neural networks to traffic cameras
Innovation has revolutionized the applications of deep neural networks and made them very useful. One example is traffic cameras, which allow different types of vehicles, other objects and living beings to be identified and classified with a certain degree of confidence.
These cameras are also able to interpret and record the trajectories of objects. It is common for these models to be accompanied by relative location algorithms within the image, so that the identified object can be inscribed in a form such as a rectangle.
With the relative position of the rectangles in the image and by using tracking algorithms, it is possible to represent the trajectories of the objects, as shown in the following image.
![]()
This has many applications. It allows us to quantify, for example, how many vehicles cross a line or how many are inside a polygon at any given time.
Artificial intelligence and deep neural networks specifically have multiple applications in our daily lives. They allow us to solve repetitive and complex tasks in a short time and with very satisfactory results. A good understanding of how they work opens up a very wide range of uses in the field of infrastructure and, just as importantly, allows them to be further expanded.



There are no comments yet